 丂僫僢僔儏嬒峵係 丂僫僢僔儏嬒峵係 |
丂 |
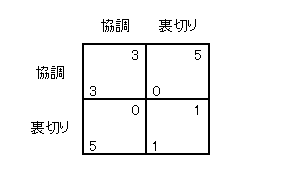
廁恖偺僕儗儞儅偺柍尷夞孞傝曉偟傪峫偊傑偡丅
孞傝曉偟僎乕儉偱愴棯偲偄偆偺偼乽偍偆傓曉偟乿乽僩儕僈乕愴棯乿偺傛偆側乽峴摦寁夋乿偺偙偲偱偡丅孞傝曉偟廁恖偺僕儗儞儅偱偺愴棯偼懠偵偳傫側傕偺偑偁傞偱偟傚偆丅嵟傕娙扨側偺偼乽偮偹偵棤愗傝乿偁傞偄偼乽偮偹偵嫤挷乿偱偡丅
偄傑偨偲偊偽僸僩儈偑乽偮偹偵棤愗傝乿傪偲偭偰偄傞偲偟傑偡丅 儅僉偼偳偆偡傞偱偟傚偆偐丠乽偮偹偵嫤挷乿偲偄偆偺偼柧傜偐偵攏幁偘偰偄傑偡丅 乽偍偆傓曉偟乿乽僩儕僈乕乿偼偳偆偱偟傚偆偐丅偙傟傕攏幁偘偰偄傑偡丅 弶夞偺嫤挷偑儉僟偵廔傢傞偩偗偱偡丅 偄傑儅僉偺偲傟傞愴棯偼乽偍偆傓曉偟乿乽僩儕僈乕乿乽偮偹偵棤愗傝乿乽偮偹偵嫤挷乿 偺4偮偟偐側偄偲偟傑偟傚偆丅偡傞偲僸僩儈偺乽偮偹偵棤愗傝乿偵懳偡傞儅僉偺嵟揔斀墳偼乽偮偹偵棤愗傝乿偱偡丅 媡偵儅僉偑乽偮偹偵棤愗傝乿傪偲偭偰偄傞偲偟傑偟傚偆丅 僸僩儈偺偲傟傞愴棯傕乽偍偆傓曉偟乿乽僩儕僈乕乿乽偮偹偵棤愗傝乿乽偮偹偵嫤挷乿 偺4偮偟偐側偄偲偟傑偡丅偡傞偲儅僉偺乽偮偹偵棤愗傝乿偵懳偡傞僸僩儈偺嵟揔斀墳偼傗偼傝乽偮偹偵棤愗傝乿偵側傝傑偡丅 乮儅僉丄僸僩儈乯亖乮偮偹偵棤愗傝丄偮偹偵棤愗傝乯偲偄偆愴棯偺慻偼乽屳偄偵嵟揔斀墳乿偵側傝傑偡丅偮傑傝僫僢僔儏嬒峵偱偡丅偙傟偑孞傝曉偟僎乕儉偱偺僫僢僔儏嬒峵偺峫偊曽偱偡丅
偄傑儅僉偲僸僩儈偼乽偍偆傓曉偟乿乽僩儕僈乕乿乽偮偹偵棤愗傝乿乽偮偹偵嫤挷乿 偺4偮偺愴棯偟偐偲傟側偄偲偟傑偡丅 僫僢僔儏嬒峵偼乮偮偹偵棤愗傝丄偮偹偵棤愗傝乯偩偗偱偟傚偆偐丅 挷傋偰傒傑偟傚偆丅傑偢棙摼昞傪偮偔傝傑偡丅
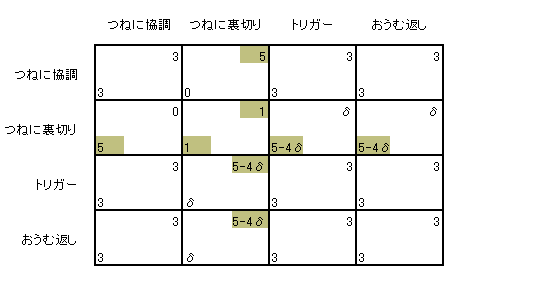
孞傝曉偟僎乕儉偱偺棙摼偼偡偱偵尒偨傛偆偵妱堷棙摼偺憤榓偱偡丅 偄傑儅僉偺彨棃棙摼偵懳偡傞妱堷場巕偑兟偱偁傞偲偟傑偟傚偆丅 偦偟偰僸僩儈偑僩儕僈乕愴棯傪偲偭偰偄傞偲偟傑偡丅 偙偺偲偒儅僉偑 乽偮偹偵嫤挷乿傪偲傞偲偡傞偲丗丂棙摼偼丂3/(1-兟) 乽偮偹偵棤愗傝乿傪偲傞偲偡傞偲丗丂棙摼偼丂5 + 兟/(1-兟) 乽僩儕僈乕乿傪偲傞偲偡傞偲丗丂棙摼偼丂3/(1-兟) 乽偍偆傓曉偟乿傪偲傞偲偡傞偲丗丂棙摼偼丂3/(1-兟) 偲側傝傑偡丅乮寁嶼偑傢偐傜側偄偲偒偼乽柍尷孞傝曉偟僎乕儉乿傪尒偰偔偩偝偄丅乯 偙傟偱棙摼昞偺堦晹偑偱偒偨偙偲偵側傝傑偡乮壓恾乯丅 |
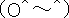
| |
| 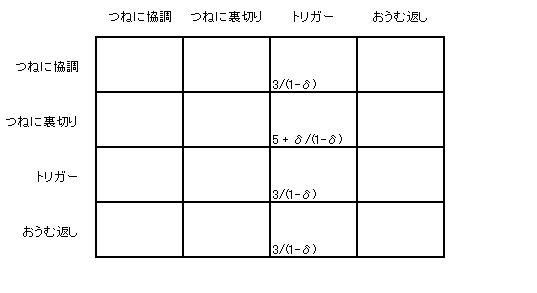 |
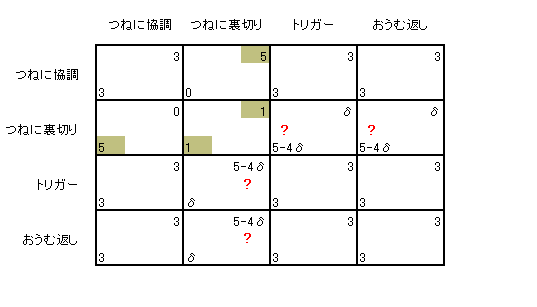
| 偙偺挷巕偱巆傝偺榞傕杽傔偰偄偔偙偲偑偱偒傑偡乮壓恾乯丅偤傂妋擣偟偰傒偰偔偩偝偄丅 僸僩儈偺乽偮偹偵嫤挷乿偵懳偟偰儅僉偑乽偮偹偵棤愗傝乿傪偲傞偲偡傞偲丄 棙摼偼5偺楢懕側偺偱憤妱堷棙摼偼 5/(1-兟) 偱偡丅僸僩儈偺乽偮偹偵棤愗傝乿偵懳偟偰 儅僉偑乽偮偹偵嫤挷乿傪偲傞偲偡傞偲丄棙摼偼0偺楢懕側偺偱憤妱堷棙摼偼 0/(1-兟) 偱偡丅 乽偮偹偵棤愗傝乿傪偲傞偲偡傞偲丄棙摼偼1偺楢懕側偺偱憤妱堷棙摼偼 1/(1-兟) 偱偡丅 乽僩儕僈乕乿傪偲傞偲偡傞偲丄棙摼偼弶夞0丄偁偲偼1偺楢懕側偺偱憤妱堷棙摼偼 0 + 兟/(1-兟) 偱偡丅僸僩儈偺乽偍偆傓曉偟乿偵懳偟偰乽偮偹偵棤愗傝乿傪偲傞偲偡傞偲丄棙摼偼弶夞5丄偁偲偼1偺楢懕側偺偱憤妱堷棙摼偼 5 + 兟/(1-兟) 偱偡丅 偙傟偱棙摼昞偺儅僉偺晹暘偼偱偒傑偟偨丅 |
|
| |
|
|  |
| 僸僩儈偺彨棃棙摼偵懳偡傞妱堷場巕傕兟偱偁傞偲偟傑偡丅 僸僩儈偺晹暘偼偙傟傪y=-x偱愜傝曉偣偽偄偄偺偱丄偗偭偒傚偔壓偺棙摼昞偑弌棃忋偑傝傑偡丅 |
|
| |
|
|  |
| 偟偐偟偙傟偱偼偁傑傝偵傕尒偵偔偄偺偱 1-兟 乮亜0乯傪妡偗偰偍偒傑偡丅 悢帤偺戝彫娭學偼曄傢傜側偄偺偱栤戣偁傝傑偣傫丅 |
|
| |
|
|  |
|
偱偼棙摼昞傪挷傋偰傒傑偟傚偆丅 0亙兟亙1 偵拲堄偟傑偡丅 傑偢傢偐傞偺偼乽偮偹偵棤愗傝乿偺慻偼傗偭傁傝僫僢僔儏嬒峵偩偲偄偆偙偲偱偡乮壓恾乯丅兟偺戝偒偝偵娭學偁傝傑偣傫丅 |
|
| |
|
|  |
|
偦偟偰
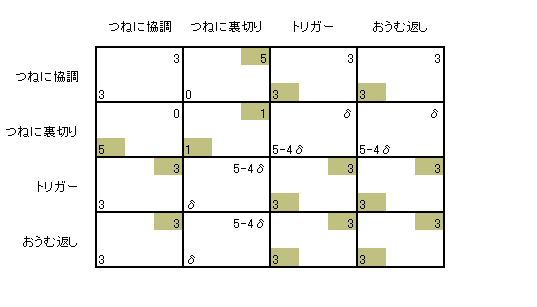
5-4兟亜3丂or丂兟亙1/2 偺偲偒 |
|
| |
|
|  |
|
5-4兟亖3丂or丂兟亖1/2 偺偲偒
|
|
| |
|
|  |
|
5-4兟亙3丂or丂兟亜1/2 偺偲偒
|
|
| |
|
|  |
|
偱偁傞偙偲偑傢偐傝傑偡丅
妱堷場巕兟偑廫暘偵戝偒偄偲偒乮兟亞1/2偺偲偒乯丄偮傑傝 乽儅僉偲僸僩儈偑廫暘恏書嫮偄偲偒乿偁傞偄偼 乽2恖偺娭學偵偮偄偰愭偺尒捠偟偑廫暘偵棫偮偲偒乿 僩儕僈乕愴棯傗偍偆傓曉偟偵傛偭偰嫤挷偑払惉偝傟偆傞偲偄偆偙偲偱偡丅 1夞偒傝偺廁恖偺僕儗儞儅偱偼偗偭偟偰幚尰偟側偄嫤挷峴摦偑 孞傝曉偟僎乕儉偵側傞偙偲偱幚尰偟傑偡丅 偙偺娙扨側儌僨儖偵偼嫮椡側娷堄偑偁傝傑偡丅 偮傑傝戞3幰乮惌晎側偳乯偺嫮惂偵棅傜側偔偰傕 僾儗乕儎乕偨偪偑張敱傪撪嵼偟偨愴棯傪偲傞偙偲偵傛偭偰 嫤挷偑払惉偝傟偆傞偲偄偆偙偲偱偡丅
仧嶲峫暥專
|